Issue 96
Term 1 2016
Information and critical literacy on the web
Kay Oddone’s article provides useful tips on how to teach students to become info-savvy learners, and how to identify quality information in an online environment that often lacks an authoritative voice.
The democratisation of content creation is a wonderful thing. Thanks to thousands of content creation and distribution platforms available, including WordPress, Scribd, Weebly, Storify, and YouTube, millions of voices which might have never been heard now have a channel to communicate their message. Whereas content previously had to pass through extensive editorial processes prior to being published, there is no such requirement on the internet.
For students, the internet is the dominant medium, and the first place they go to for information. In a world of information overload, it is vital for students to be able to determine the validity and appropriateness of the information that they find.
For teachers, it is not only necessary to have these skills themselves, but also to be able to educate students in becoming informed, literate, self-directed learners. Mandy Lupton (2014) has found that inquiry skills and information literacy are embedded in the Australian Curriculum in the subject areas of Science, History, Geography, Economics and Business, Civics and Citizenship, and Digital Technologies; and in the general capabilities of Critical and Creative Thinking (CCT) and Information and Communication Technologies (ICT). An effective researcher and critical thinker should be able to identify quality information, and know where to source it from.
Alan November, an international consultant known for his work in educational technology, presents a great strategy to be applied when you need to confirm the reliability of a source of information. He calls it the ‘REAL’ test. REAL stands for:
Read the URL
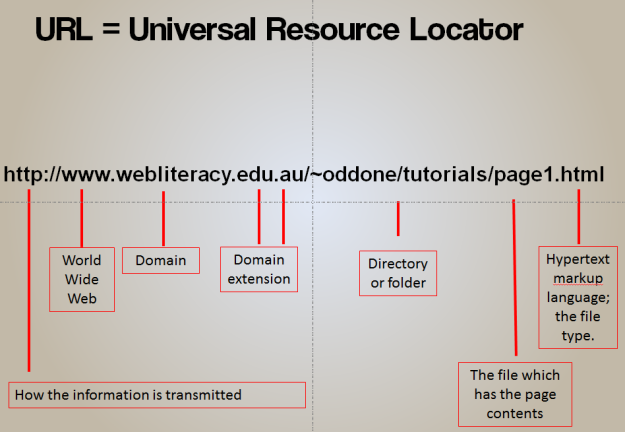
Breakdown of a standard URL
When researching or browsing the web, it is easy to follow one link after another, ending up somewhere completely different to where you started. Reading the URL is the best way to answer the question ‘where am I?’ It is a good idea to get in the habit of looking at the URL regularly to check the credibility of the website and its information. The diagram above provides a breakdown of a standard web address.
Most web addresses begin with the letters ‘http’, which stands for Hypertext Transfer Protocol – the protocol which allows two computers to communicate. If you see an ‘s’ added (https), this indicates a secure protocol is being used. You are most likely to see the secure protocol being used on sites where personal information such as banking details are being communicated, like when shopping online.
The domain is the part of the URL which commonly identifies which company, agency or organisation may be either directly responsible for the information, or is providing the computer space where the information is stored. The domain name may give clues as to whether the information can be trusted, but it is not the only part of the URL that is useful. The domain extension usually identifies the type of organisation that created or sponsored the resource. For example, .com is used for company or commercial sites, .edu for educational sites, .gov for government sites, and .net for internet service providers or other types of networks.
If the domain extension is two letters, it identifies a country. For example, .us is used for the United States, .uk for the United Kingdom, .mx for Mexico, and .ca for Canada. This can be useful if you are researching country-specific information. I often add site:.au to my searches if I am only looking for Australian results.
Information after the main web address is the file path, which shows where the page you are looking at is stored. The file path in the URL breakdown image provided is /~oddone/tutorials/ page1. While the domain name is useful to identify the validity of a website, the file path is also important to look at.
If the file path has a personal name, a tilde (~), a percentage sign, or the words ‘user’, ‘people’ or ‘members’, it suggests you are on a personal site. This is common on educational websites, in which case the information does not have the same quality assurance as the institution’s official webpage.
Examine the site’s content and history
The currency of a webpage can often be determined by the date at the base of the page. However, this only tells you when the page was copyrighted or last published. How can you see if the information is regularly updated, or if the website has changed over time? We can chart the progress or history of a website thanks to the Internet Archive Wayback Machine.
The Wayback Machine allows you to browse through 450 billion webpages archived from 1996 to now. To use this site, enter the URL that you would like to research, click the ‘Browse history’ button, and if the search is successful, select from the archived dates available. This gives you an idea of how the site has developed over time, whether changes have been made, and how regularly the information is updated.
Ask about the publisher or the author
Using a domain lookup service such as easywhois can often provide details about who owns a website or who has published its material.
Alan November uses martinlutherking. org as an example as it is one that students could easily use: it appears high in search results and looks appealing to students. Using easywhois.com to find the owner of the site reveals it is hosted by the server stormfront.org. If you search ‘stormfront’, you will find that it is a white supremacist organisation. If you are looking at information which could be controversial or open to bias, or if you would like to know more about a website, this can be a handy tool to use.
Look at the links
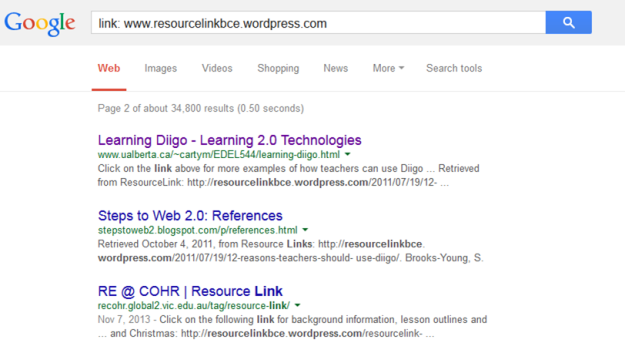
Screenshot of a Google search to determine what external websites link to a URL
Students usually search using only one search engine. Many students also believe that the top hits are the most important, which is not always the case. Many businesses specialise in Search Engine Optimisation (SEO), which is all about improving the visibility of a webpage in search results in order to receive more website visitors. The process of getting a website to appear high in the listings returned by a search is based on a complex series of strategies, including how the website has been built, and what keywords are embedded in the website’s metadata.
A search engine looks at a search query and tries to return relevant content. When several pages have similar titles or content, it is the links to the page that make the difference. Wikipedia, for example, usually appears at the top of a search because it is popular, and also because there are so many sites – internal and external – that link to each Wikipedia page.
You can find out what websites link to the webpage you are evaluating by typing the word link: into the search bar, directly followed by the URL. It will then return a list of webpages that link to that site. Often, the more links the website has to it, the higher it appears in search results.
This is a good way to check a website’s credibility: for example, if an educational institution considers a website valuable enough to share with their readers, it is more likely that the content is reliable. The links to a site will allow students to build a map of related commentary: who uses this site and considers it important enough to share?
Online resources to support information literacy
Verification Handbook
The Verification Handbook is an interesting read that offers a range of tools and strategies that journalists use to verify information, using real case studies as examples. Of course, students who are researching will not necessarily go to the same lengths that journalists do to identify the veracity of information they find online, but it is useful to be aware of strategies that are easy to apply if they are not sure of the accuracy of information.
Tin Eye
A useful tool for establishing the provenance of images is the Tin Eye reverse image search tool. Tin Eye begins with an image, and then searches back to attempt to establish where the image came from, how it is being used, if modified versions of the image exist, or if there is a higher resolution version available. This is particularly useful if you suspect that an image has been doctored. You can install the Tin Eye plugin to your browser, or you can use the feature directly from the website.
To access more resources to support information literacy, head to https://www.pinterest.com/kayo287/criticalliteracy-with-online-resources/.
References
- Lupton, M 2014, ‘Inquiry skills across the Australian curriculum’, https://inquirylearningblog.wordpress.com/2014/05/12/inquiry-skills-across-the-australian-curriculum
- November, A n.d., ‘Education resources for web learning’, November Learning, http://novemberlearning.com/educationalresources-for-educators/information-literacy-resources/.
Image credits
- The Google logo is a registered trademark of Google Inc. Used with permission.
Article republished with permission.
To view Kay's original blog posts, please visit https://linkinglearning.wordpress.com/2014/10/13/becoming-info-savvy-information-and-critical-literacy-in-the-web-world/.

Kay Oddone
Teacher librarian and PhD student